![]()
![]()
|
Fonte: www.keinpfusch.net https://comedonchisciotte.org/ 20 marzo 2018
Cambridge Analytica, II (Sto vedendo scrivere dalla stampa cose indegne, quindi spieghiamo meglio)
La stampa italiana sta cercando di “troncare e sopire” quanto e’ stato fatto da Cambridge Analytica, in una maniera che personalmente trovo indegna. La stanno facendo passare per un furto di dati privati, ovvero per qualche cosa che ha funzionato carpendo dati scritti sul social network. Ha ridotto cioe’ la cosa ad un fenomeno di privacy, che potrebbe apparentemente essere risolto decidendo cosa scrivere di se’ o meno.
Ma le cose non stanno cosi’. Vi rimando di nuovo all’articolo che ho gia’ postato: https://www.pnas.org/content/110/15/5802
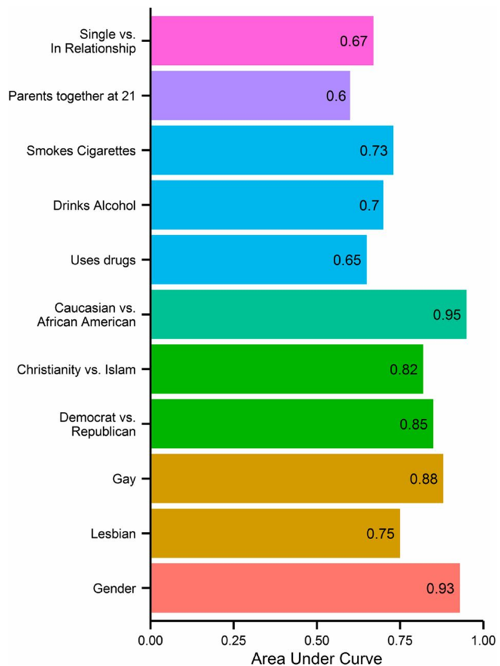
Chi ha le competenze per capirlo, vede bene l’orrore sottostante. Provero’ dunque a spiegarlo a coloro che non riescono a percepire il punto. Il fatto e’ semplice: su facebook non si vedono solo le cose che scrivete, ma anche quelle che NON scrivete. Siete trasparenti. L’articolo spiega un fenomeno noto (e controverso), che e’ quello della causalita’ di Granger, e la sua applicazione all’analisi del comportamento umano partendo da informazioni piu’ o meno casuali. Che cosa significa? Supponiamo che il mio sistema di Big Data spazzoli tutti i prodotti di un supermercato, senza sapere altro di quanto accade fuori. Quello che notera’ e’ che quando sull’etichetta c’e’ scritto, diciamo, “pelati”, dentro ci sono dei pelati. Se dovesse costruire un metodo predittivo del contenuto, deciderebbe che il contenuto sia un effetto dell’etichetta. Questo perche’ il contenuto informativo dell’etichetta si conserva nel prodotto. C’e’ scritto “pelati” e dentro ci sono i pelati. Ovviamente non e’ una vera e propria relazione di causa/effetto: se prendo una scatoletta vuota e ci metto sopra l’etichetta, essa non causa la comparsa dei pomodori, come se fosse una relazione fisica di causalita’ di Poisson. Per questo in garage ho una lattina di pelati con dentro dei chiodi, senza che si trasformino in pomodori. Ma questa relazione di causalita’ funziona, ed e’ predittiva, dentro il supermercato. Sapendo quanto succede fuori possiamo facilmente comprendere che ci sia da qualche parte una ditta che scientemente etichetta il prodotto. Ma questo la macchina non lo sapeva. La macchina deduce una verita’ locale, che e’ vera in praticamente ogni supermercato del mondo, e dice che si possa prevedere il contenuto della lattina leggendo l’etichetta, come se l’etichetta fosse la causa ed il contenuto un effetto. Ecco, supponete che il supermercato sia facebook. Voi siate dentro la lattina, e vogliamo sapere cosa c’e’ dentro la lattina osservando le etichette, dove le etichette sono tutto quello che dite. Ma attenzione: non ci serve che l’etichetta dica esplicitamente cosa c’e’ dentro il barattolo. E’ come se lo deducessimo dallo scaffale, o sapendo che il tale prodotto arriva il lunedi’ e finisce il mercoledi’, e da altre cose che non sono scritte esplicitamente. Allora, supponiamo che una persona sia gay. Un cosiddetto “closet gay”. Uno nascosto. Non dira’ MAI su facebook di essere gay, magari e’ sposato e si comporta come chiunque altro. Ma la macchina ha esaminato tutte le possibili etichette e tutte le possibili correlazioni. E ha scoperto che un certo insieme di “etichette”, che potrebbero essere {“cravatta”, “campeggio”, “station wagon”, X,Y,Z,K,J,I… } sono consistenti in tutti i gay. E quindi, vi puo’ sgamare semplicemente osservando ALTRI “tratti caratteristici”, che NON hanno apparentemente nulla a che vedere con la dimensione che si vuole osservare. Ecco le percentuali di efficacia.
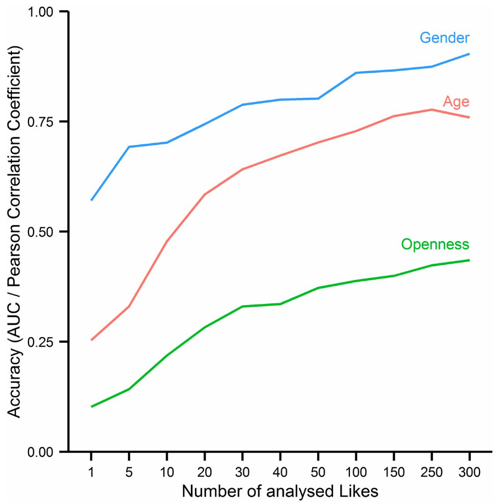
Queste dimensioni sono state estrapolate su volontari cui era chiesto di NON pubblicare dati nelle dimensioni in questione. I gay non dovevano dire di esserlo, eccetera. Dovevano solo dare dei “like” su temi che non riguardassero esplicitamente o direttamente la preferenza in questione. Significa che non parliamo di un problema di privacy. Non parliamo di un’azienda che ha saputo cio’ che gli utenti hanno scritto. Parliamo di un’azienda che ha saputo cio’ che gli utenti NON hanno scritto. Significa che facebook puo’ inferire , dopo circa 300 likes, anche quello che NON ci avete scritto su di voi.
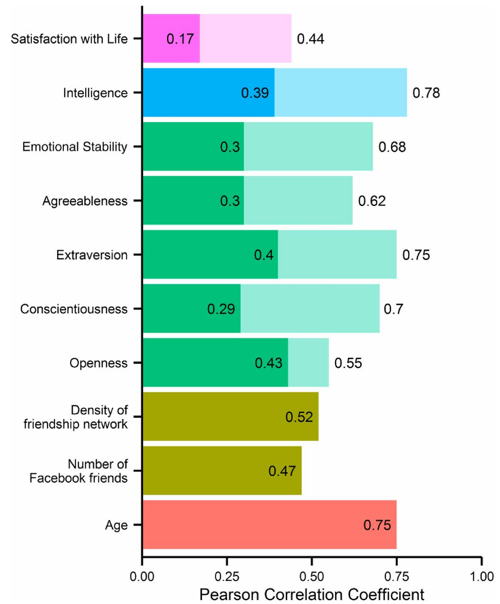
Ludicamente parlando possiamo pensare che un algoritmo capace di individuare ogni moglie zozzona del paese sia una cosa fantastica. Qualcosa capace di profilare ogni donna su Facebook e sapere se sia il tipo che tradisce il marito e’ praticamente la trama di molti film porno degli anni ‘80. Sembra un prodotto della Same Govj Il problema e’ che questa roba esiste. E dopo 300 likes, anche sconnessi dall’informazione che volevate, e’ possibile estrapolare cose su di voi. Quello che ha fatto Cambridge Analytics e’ stato di applicarlo alla politica ed alle opinioni. Ha stabilito che le persone contrarie alla politica di israele siano caratterizzate da una n-pla {“scarpe nike”, “kit kat”, X,Y,Z,I,J,K….} e si e’ sforzata di prevedere il contenuto della lattina usando le “etichette” : una n-pla di queste preferenze consiste nell’etichetta. Quando Trump ha chiesto loro di trovare 200.000 persone che voterebbero per lui se fosse amico di Israele, CA ha risposto non dicendo cose come “il tuo elettore tipo e’ bianco, disoccupato, poco scolarizzato.” . Ha risposto con una serie di nomi e cognomi e luoghi di residenza pescati su Facebook. A Trump non e’ rimasto altro che mandar loro una lettera a casa. Quelli contrari ad Israele erano stati esclusi dalla lista. Ma c’e’ di piu’, ed e’ il problema degli “influencer”. Supponiamo di voler raggiungere tutti gli elettori, ma non siamo sicuri che abbiano deciso, e anche mandare una lettera per invitarli non funziona. Potremmo usare il passaparola, nel senso che magari se i nostri elettori indecisi sentissero parlare bene di noi, potremmo convincerli. Ma da chi devono sentir parlare bene? In questa catena del passaparola, da chi cominciamo? Qual’e’ l’entrypoint? Come vedete nell’ultimo grafico, era stimata una quantita’ detta “openness”. Si tratta dell’attitudine ad essere degli “early adopters”. Gli early adopters sono persone che si tuffano su ogni novita’, ma se insieme ci calcoliamo la dimensione dell’intelligenza, abbiamo le persone che salgono sui trend vincenti. Ecco un elenco delle dimensioni utilizzate:
Avuti questi, trasciniamo gli altri. Quindi, per avere i 200.000 indecisi, Trump ha solo dovuto chiedere i nomi dei primi 200 early adopters. I nomi ed i cognomi estratti dai contatti di Facebook. Magari li hanno contattati personalmente, casa per casa. Duecento non e’ un numero grande. Ma se il successo sui 200 early adopters della zona e’ stato alto, Trump sapeva benissimo di avere dalla sua parte tutti e 200.000 gli elettori indecisi. Questo ovviamente apre la porta a scenari orribili. Come ho detto, oggi come oggi per trovare Anna Fank bastano pochi minuti, ma era una figura retorica. In realta’ la GeStaPo vi verrebbe a prendere PRIMA che voi possiate decidere di ospitare la sua famiglia, semplicemente calcolando che la vostra personalita’ sia quella dell’oppositore politico, anche PRIMA che voi lo diventiate.
Un regime basato su un sistema simile puo’ prendere gli oppositori addirittura PRIMA che decidano di diventarlo. Se siete su Facebook e un tempo avete tradito il partner, non importa che lo diciate o meno. Facebook lo ha calcolato. Se siete su Facebook e siete “closet gay” non importa quanto bene lo nascondiate o se siete addirittura sposati e non avete avuto alcun contatto : Facebook sa di voi. Ha profilato la vostra psiche.
Quella roba esiste. L’ articolo che ho mostrato https://www.pnas.org/content/pnas/110/15/5802.full.pdf e’ un lavoro scientifico. Ha avuto peer review positive. Esiste.
Il reato ideato da Orwell, lo Psicoreato, non solo e’ diagnosticabile, ma non mediante microfoni e spionaggio come pensava Orwell. Orwell era un ottimista, perche’ pensava che in qualche modo voi doveste pronunciare, esternalizzare la cosa che pensate per poi procedere a perseguirvi. Orwell rimaneva cioe’ convinto che nessuno potesse leggere il vostro pensiero.
Ecco, le cose non stanno cosi’. Il vostro pensiero puo’ essere profilato, si possono sapere di voi anche le cose che non dite, che tenete nascoste, che pensavate di avere solo in mente. E lo si puo’ fare osservandovi mentre girate su internet. Mentre mettete i “like”: anche cose innocentissime come marche di scarpe e barrette di cioccolato possono dire molto sulle vostre preferenze politiche. La stampa italiana sta facendo passare questa cosa per “furto di dati” o per “accesso non autorizzato”, ma in realta’ il problema non e’ che hanno rubato dati da Facebook o sono entrati illegalmente su Facebook. Hanno rubato dati dalla vostra mente, e sono entrati illegalmente nella vostra mente.
Spero che cosi’ sia piu’ chiaro.
I grandi social network sono inerentemente malvagi. Statene alla larga. Se potete, fatevi un proxy DNS e bannate gia’ a livello di risoluzione ogni loro dominio, sottodominio e/o CDN. Link:https://www.keinpfusch.net/post/2018-03-19-7397-9b5fe50d4d42a95ea6bd5cc6e472cad3/ 19.03.2018 |